State of training on Metal
TL;DR
- Using the nightly pytorch build, I am no longer getting CPU fallback warnings due to missing kernels when training nanoGPT on Metal.
- However — on my Macbook, at least — training on Metal is significantly slower with
torch.compilethan without it (though still faster than training on the CPU).
Background
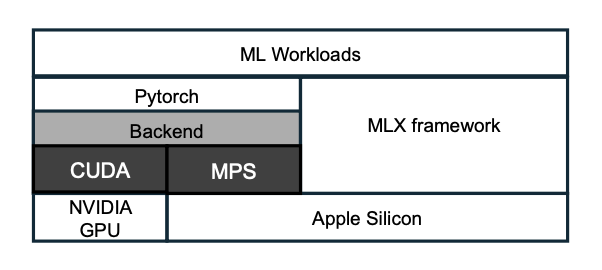
- Apple Silicon’s unified memory architecture makes the Mac a potentially attractive platform for ML training, particularly when it comes to models too large to fit into memory on a single NVIDIA card.
- To take advantage of this, though, you need an ML framework with good Metal (MPS) support, ideally one capable of optimizing computational graphs through compilation (JIT or otherwise).
- A Metal backend was first added to PyTorch back in 2022. While much progress has been made since then, MPS Ops coverage is still incomplete.
- For example, if you try to run
torch.svdon MPS, you get this error: “The operatoraten::linalg_svdis not currently supported on the MPS backend and will fall back to run on the CPU. This may have performance implications.”. - As of now, over 70 ops are tagged with either “To triage” or “To be implemented”.
- There is a Github issue you can comment on to drive prioritization.
- For example, if you try to run
- Apple has recently released its own ML framework, called MLX, which supports not only MPS but also Neural Engine (ANE). Allegedly, anyway — asitop didn’t pick up any ANE usage during my MLX runs.
- Unlike Core ML, which is primary geared towards inference and fine-tuning, MLX is intended for training models from scratch in a flexible way, similar to PyTorch or JAX.
- There are no tools for automatically converting PyTorch (or JAX) models to MLX the way you can covert models to Core ML with coremltools, though.
- You can certainly port the training loop from PyTorch to MLX manually, but it’s non-trivial.
- JAX has historically prioritized TPUs when it comes to accelerators, which makes sense given its Google lineage. While support for MPS in JAX is in the works, it’s still experimental at this point.
- Then there’s tinygrad, which aims to provide first-class support for MPS out of the box.
- As with MLX, there is no way to automatically convert PyTorch models to tinygrad.
- A number of popular models have been ported, though. Here is what the training loop looks like.
nanoGPT as a training benchmark
- nanoGPT is Adrej Karpathy’s from-scratch implementation of GPT-2 in PyTorch.
- There are two main scripts,
train.pyfor training andsample.pyfor inference. - The default is to use NVIDIA GPUs and JIT-compile the model into optimized kernels via
torch.compile, but you can override this using the--deviceand--compilecommand-line switches, respectively. - When nanoGPT was first released in 2022, MPS support in PyTorch was still nascent. Training on the Mac was limited to the CPU in practice, so much so that the quick start section branched on “I have a GPU” vs “I only have a macbook”.
- Things have improved a lot since then, though, as you can see from this github issue.
Training nanoGPT on the Mac in September 2025
Setup
This assumes you have uv installed:
git clone https://github.com/karpathy/nanoGPT.git
cd nanoGPT
uv venv
uv pip install numpy transformers datasets tiktoken wandb tqdm
uv pip install --pre torch --index-url https://download.pytorch.org/whl/nightly/cpu
uv run data/shakespeare_char/prepare.py
MPS training, without torch.compile
/usr/bin/time uv run train.py config/train_shakespeare_char.py --device=mps --compile=False
...
step 0: train loss 4.2874, val loss 4.2823
iter 0: loss 4.2639, time 25857.56ms, mfu -100.00%
iter 10: loss 3.1459, time 220.50ms, mfu 1.69%
iter 20: loss 2.7319, time 221.44ms, mfu 1.69%
iter 30: loss 2.6226, time 221.30ms, mfu 1.69%
iter 40: loss 2.5756, time 220.74ms, mfu 1.69%
iter 50: loss 2.5239, time 220.24ms, mfu 1.69%
...
iter 4990: loss 0.8203, time 276.23ms, mfu 1.33%
step 5000: train loss 0.6166, val loss 1.7099
iter 5000: loss 0.8117, time 33010.34ms, mfu 1.19%
3588.66 real 90.18 user 32.03 sys
MPS training, with torch.compile
/usr/bin/time uv run train.py config/train_shakespeare_char.py --device=mps --compile=True
...
step 0: train loss 4.2874, val loss 4.2823
iter 0: loss 4.2672, time 85292.53ms, mfu -100.00%
iter 10: loss 3.1471, time 304.79ms, mfu 1.22%
iter 20: loss 2.7730, time 305.33ms, mfu 1.22%
iter 30: loss 2.6538, time 306.39ms, mfu 1.22%
iter 40: loss 2.5960, time 306.01ms, mfu 1.22%
iter 50: loss 2.5479, time 305.41ms, mfu 1.22%
...
iter 4990: loss 0.8286, time 329.89ms, mfu 1.11%
step 5000: train loss 0.6221, val loss 1.7106
iter 5000: loss 0.8242, time 1255915.73ms, mfu 1.00%
39039.74 real 72.21 user 21.28 sys
CPU training
uv run train.py config/train_shakespeare_char.py --device=cpu --compile=False
...
step 0: train loss 4.2874, val loss 4.2823
iter 0: loss 4.2655, time 119984.47ms, mfu -100.00%
iter 10: loss 3.1338, time 1973.80ms, mfu 0.19%
iter 20: loss 2.7556, time 1984.34ms, mfu 0.19%
iter 30: loss 2.6094, time 1988.45ms, mfu 0.19%
iter 40: loss 2.5535, time 1983.75ms, mfu 0.19%
iter 50: loss 2.5237, time 2003.05ms, mfu 0.19%
Questions and Observations
- Based on iterations 10-50, MPS training without
torch.compileis almost an order of magnitude faster than CPU training (221ms vs 1986ms). This suggests that PyTorch support for MPS is fairly mature. - Something funny happens when you turn on
torch.compile, though. First off, the individual iterations get about 1.4 times slower compared to MPS with no compilation (306ms vs 221ms). Moreover, the overall training run takes more than 10 times as long (almost 11 hours instead of around an hour). - I’m not sure what’s going on. Perhaps the auto-generated MPS kernels are less efficient than the hand-tuned ones, or maybe there is a more fundamental issue such as silently falling back to the CPU. Either way, it seems that
torch.compileon MPS isn’t quite ready for prime time. - At any rate, you can use asitop to confirm that GPU usage is at 100% when training on MPS, whether
torch.compileis used or not.